You can select XML as a file type in the dialog box that displays when you select Rows>Import in the Report painter. (The Preview view must be open to enable the Rows>Import menu item.)
Data can be imported with or without a template. To import data without a template, the data must correspond to the report column definition. The text content of the XML elements must match the column order, column type, and validation requirements of the report columns.
Composite, OLE, and Graph reports
Composite, OLE, and Graph reports cannot be imported using a template. You must use the default format.
If the XML document or string from which you want to import data does not correspond to the report column definition, or if you want to import attribute values, you must use a template.
If a schema is associated with the XML to be imported, you must create a template that reflects the schema.
For complex, nested XML with row data in an iterative structure, you may need to design a structure that uses several linked report definitions to import the data. Each report must define the structure of a block of iterative data with respect to the root element. Importing the data into the reports would require multiple import passes using different import templates.
Defining import templates
The XML import template can be defined in the Export/Import Template view for XML. If you are defining a template for use only as an import template, do not include InfoMaker expressions, text, comments, and processing instructions. These items are ignored when data is imported.
Only mappings from report columns to XML elements and attributes that follow the Starts Detail marker in the template are used for import. Element and attribute contents in the header section are also ignored. If the Starts Detail marker does not exist, all element and attribute to column mappings within the template are used for import. For more information about the Starts Detail marker, see The Detail Start element.
Matching template structure to XML
An XML import template must map the XML element and attribute names in the XML document to report column names, and it must reflect the nesting of elements and attributes in the XML.
The order of elements and attributes with column reference content in the template does not have to match the order of columns within the report, because import values are located by name match and nesting depth within the XML. However, the order of elements and attributes in the template must match the order in which elements and attributes occur in the XML. Each element or attribute that has column reference content in the template must occur in each row in the XML document or string. The required elements and attributes in the XML can be empty.
If an element or attribute does not occur in the XML document, the report import column remains empty.
The data for the report is held in the columns of the data table. Some data columns, such as those used for computed fields, may not have an associated control. To import data into a column that has no control reference, add a child InfoMaker expression that contains the column name.
Remove tab characters
When you select a column name in the InfoMaker expression dialog box, tab characters are added before and after the name. You should remove these characters before saving the expression.
Importing data with group headers
For XML import using a template, element and attribute contents in the header section are ignored. However, if the Starts Detail marker does not exist, all element and attribute to column mappings within the template are used for import. This has the following implications for reports with group headers:
-
If data is imported to a Group report using a template that has a Starts Detail marker, the group header data is not imported because import starts importing from the Starts Detail location.
-
If the Group report has one group and the import template has no Starts Detail marker, all the data is imported successfully.
Nested groups cannot be imported
If the Group report has nested groups, the data cannot be imported successfully even if the Starts Detail marker in the import template is turned off.
Report columns cannot be referenced twice for import. A second column reference to a report column within an XML import template is ignored.
An XML element or attribute name whose content references a report column for import must be unique within the level of nesting. It cannot occur twice in the template at the same nesting level.
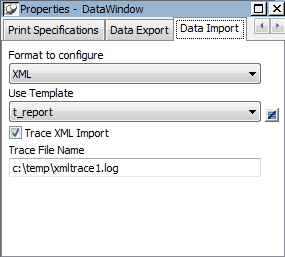
Setting the import template
The names of all templates for the current report display in the Use Template drop-down list on the Data Import page in the Properties view.
Using export templates for import
If you have already defined an export template for a report, you can use it as an import template, but only the mapping of column names to element attribute names is used for import. All other information in the template is ignored.
The template you select in the list box is used to conform the XML imported to the specifications defined in the named template.
The Data Import page also contains a property that enables you to create a trace log of the import. See Tracing import.
This example uses a report that includes the columns emp_id, emp_fname, emp_lname, and dept_id. The template used in this example includes only these columns. Any other columns in the report remain empty when you import using this template.
To illustrate how template import works, create a new template that has one element in the header section, called before_detail_marker. This element contains a column reference to the emp_id column.
The Detail Start element, employee, has an attribute, dept_id, whose value is a control reference to the column dept_id. It also has three children:
-
The emp_id element contains a column reference to the emp_id column.
-
The emp_fname element contains static text.
-
The name element has two children, emp_fname and emp_lname, that contain column references to those columns.
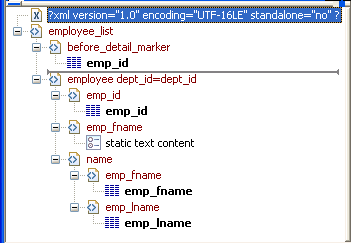
The template exports and imports the dept_id report column using the attribute of the employee element. It exports and imports the emp_id, emp_fname, and emp_lname columns using the column references in the elements. The following shows the beginning of the XML exported using this template:
<?xml version="1.0" encoding="UTF-16LE" standalone="no"?> <employee_list> <before_detail_marker>102</before_detail_marker> <employee dept_id="100"> <emp_id>102</emp_id> <emp_fname>static text content</emp_fname> <name> <emp_fname>Fran</emp_fname> <emp_lname>Whitney</emp_lname> </name> </employee> <employee dept_id="100"> <emp_id>105</emp_id> <emp_fname>static text content</emp_fname> <name> <emp_fname>Matthew</emp_fname> <emp_lname>Cobb</emp_lname> </name> </employee> ...
The exported XML can be reimported into the report columns dept_id, emp_id, emp_fname, and emp_lname. Before importing, you must set the import template on the Data Import page in the Properties view.
The following items are exported, but ignored on import:
-
The before_detail_marker element is ignored because it is in the header section.
-
The first occurrence of the element tag name emp_fname is ignored because it does not contain a mapping to a report column name.
If you change the nesting of the emp_fname and emp_lname elements inside the name element, the import fails because the order of the elements and the nesting in the XML and the template must match.
When there is no import template assigned to a report with the UseTemplate property, InfoMaker attempts to import the data using the default mechanism described in this section.
Elements that contain text
The text between the start and end tags for each element can be imported if the XML document data corresponds to the report column definition. For example, this is the case if the XML was exported from InfoMaker using the default XML export template.
The text content of the XML elements must match the column order, column type, and validation requirements of the report columns.
All element text contents are imported in order of occurrence. Any possible nesting is disregarded. The import process ignores tag names of the elements, attributes, and any other content of the XML document.
Empty elements
Empty elements (elements that have no content between the start and end tags) are imported as empty values into the report column. If the element text contains only white space, carriage returns, and new line or tab characters, the element is treated as an empty element.
Any attributes of empty elements are ignored.
Elements with non-text content
If the element has no text content, but does contain comments, processing instructions, or any other content, it is not regarded as an empty element and is skipped for import.
The three XML documents that follow all show the same result when you select Rows>Import in the Report painter. The Preview view must be open and selected to enable the Rows>Import menu item.
The report has five columns: emp_id, emp_fname, emp_lname, phone, and birth_date.
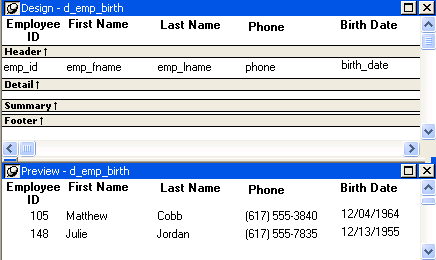
Example 1
This example contains two rows, each with five elements that match the column order, type, and validation requirements for the report.
<?xml version="1.0"?> <d_emp_birth_listing> <d_emp_birth_row> <element_1>105</element_1> <element_2>Matthew</element_2> <element_3>Cobb</element_3> <element_4>6175553840</element_4> <element_5>04/12/1960</element_5> </d_emp_birth_row> <d_emp_birth_row> <element_1>148</element_1> <element_2>Julie</element_2> <element_3>Jordan</element_3> <element_4>6175557835</element_4> <element_5>11/12/1951</element_5> </d_emp_birth_row> </d_emp_birth_listing>
Example 2
In this example, the elements are not contained in rows, but they still match the report.
<?xml version="1.0"?> <root_element> <element_1>105</element_1> <element_2>Matthew</element_2> <element_3>Cobb</element_3> <element_4>6175553840</element_4> <element_5>04/12/1960</element_5> <element_6>148</element_6> <element_7>Julie</element_7> <element_8>Jordan</element_8> <element_9>6175557835</element_9> <element_10>11/12/1951</element_10> </root_element>
Example 3
The comments and processing instructions in this example are not imported. The nesting of the <first> and <last> elements within the <Name> element is ignored.
<?xml version="1.0"?> <root_element> <!-- some comment --> <row_element><?process me="no"?>105<name Title="Mr"> <first>Matthew</first> <last>Cobb</last> </name> <!-- another comment --> <phone>6175553840</phone> <birthdate>04/12/1960</birthdate> </row_element> <row_element>148<name Title="Ms"> <first>Julie</first> <last>Jordan</last> </name> <phone>6175557835</phone> <birthdate>11/12/1951</birthdate> </row_element> </root_element>
Result
All three XML documents produce this result:
|
emp_id |
emp_fname |
emp_lname |
phone |
birth_date |
|---|---|---|---|---|
|
105 |
Matthew |
Cobb |
6175553840 |
04/12/1960 |
|
148 |
Julie |
Jordan |
6175557835 |
11/12/1951 |
Example 4
This example uses the same report, but there are two empty elements in the XML document. The first has no content, and the second has an attribute but no content. Both are imported as empty elements.
<?xml version="1.0"?> <root_element> <!-- some comment --> <row_element> <?process me="no"?>105<name Title="Mr"> <first>Matthew</first> <!-- another comment --> <last>Cobb</last> </name> <empty></empty> <birthdate>04/12/1960</birthdate> </row_element> <row_element>148<name Title="Ms"> <empty attribute1 = "blue"></empty> <last>Jordan</last> </name> <phone>6175557835</phone> <birthdate>11/12/1951</birthdate> </row_element> </root_element>
Result
The XML document produces this result:
|
emp_id |
emp_fname |
emp_lname |
phone |
birth_date |
|---|---|---|---|---|
|
105 |
Matthew |
Cobb |
|
04/12/1960 |
|
148 |
|
Jordan |
6175557835 |
11/12/1951 |
When you import data from XML with or without a template, you can create a trace log to verify that the import process worked correctly. The trace log shows whether a template was used and if so which template, and it shows which elements and rows were imported.
To create a trace log, select the Trace XML Import check box on in the Data Import page in the Properties view and specify the name and location of the log file in the Trace File Name box. If you do not specify a name for the trace file, InfoMaker generates a trace file with the name pbxmtrc.log in the current directory.
Example: default import
The following trace log shows a default import of the department table in the PB Demo database:
/*--------------------------------------------------*/ /* 09/10/2005 18:26 */ /*--------------------------------------------------*/ CREATING SAX PARSER. NO XML IMPORT TEMPLATE SET - STARTING XML DEFAULT IMPORT. DATAWINDOW ROWSIZE USED FOR IMPORT: 3 ELEMENT: dept_id: 100ELEMENT: dept_name: R & DELEMENT: dept_head_id: 501 --- ROWELEMENT: dept_id: 200ELEMENT: dept_name: SalesELEMENT: dept_head_id: 902 --- ROWELEMENT: dept_id: 300ELEMENT: dept_name: FinanceELEMENT: dept_head_id: 1293 --- ROWELEMENT: dept_id: 400ELEMENT: dept_name: MarketingELEMENT: dept_head_id: 1576 --- ROWELEMENT: dept_id: 500ELEMENT: dept_name: ShippingELEMENT: dept_head_id: 703 --- ROW
Example: template import
The following trace log shows a template import of the department table. The template used is named t_1. Notice that the report column dept_id is referenced twice, as both an attribute and a column. The second occurrence is ignored for the template import, as described in Restrictions. The Detail Start element has an implicit attribute named __pbband which is also ignored.
/*---------------------------------------------------*/ /* 09/10/2005 18:25 */ /*---------------------------------------------------*/ CREATING SAX PARSER. USING XML IMPORT TEMPLATE: t_1 XML NAMES MAPPING TO DATAWINDOW IMPORT COLUMNS: ATTRIBUTE: /d_dept/d_dept_row NAME: '__pbband' >>> RESERVED TEMPLATE NAME - ITEM WILL BE IGNOREDATTRIBUTE: /d_dept/d_dept_row/dept_id_xml_name NAME: 'dept_id' DATAWINDOW COLUMN: 1, NAME: 'dept_id' ELEMENT: /d_dept/d_dept_row/dept_id_xml_name >>> DUPLICATE DATAWINDOW COLUMN REFERENCE: 1, NAME: 'dept_id' - ITEM WILL BE IGNOREDELEMENT: /d_dept/d_dept_row/dept_head_idDATAWINDOW COLUMN: 3, NAME: 'dept_head_id' ELEMENT: /d_dept/d_dept_row/dept_nameDATAWINDOW COLUMN: 2, NAME: 'dept_name' ATTRIBUTE: /d_dept/d_dept_row/dept_id_xml_name NAME: 'dept_id': 100ELEMENT: /d_dept/d_dept_row/dept_head_id: 501ELEMENT: /d_dept/d_dept_row/dept_name: R & D --- ROWATTRIBUTE: /d_dept/d_dept_row/dept_id_xml_name NAME: 'dept_id': 200ELEMENT: /d_dept/d_dept_row/dept_head_id: 902ELEMENT: /d_dept/d_dept_row/dept_name: Sales --- ROWATTRIBUTE: /d_dept/d_dept_row/dept_id_xml_name NAME: 'dept_id': 300ELEMENT: /d_dept/d_dept_row/dept_head_id: 1293ELEMENT: /d_dept/d_dept_row/dept_name: Finance --- ROWATTRIBUTE: /d_dept/d_dept_row/dept_id_xml_name NAME: 'dept_id': 400ELEMENT: /d_dept/d_dept_row/dept_head_id: 1576ELEMENT: /d_dept/d_dept_row/dept_name: Marketing --- ROWATTRIBUTE: /d_dept/d_dept_row/dept_id_xml_name NAME: 'dept_id': 500ELEMENT: /d_dept/d_dept_row/dept_head_id: 703ELEMENT: /d_dept/d_dept_row/dept_name: Shipping --- ROW