Data Transfer is a set of tools for viewing and modifying Charset and Encoding.
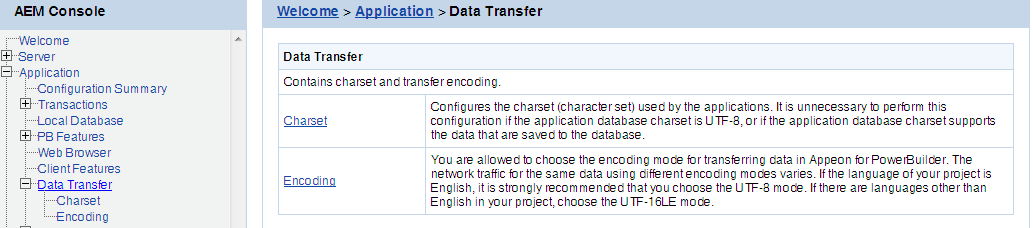
The character set conversion can be enabled at the data source level for each application if you specify the input Charset and database Charset for the cache in AEM.
You will find the Charset tool useful when:
-
The database uses non-UTF-8 character set, and
-
The language display of the application has error code in it
Otherwise, it is unnecessary to use this tool.
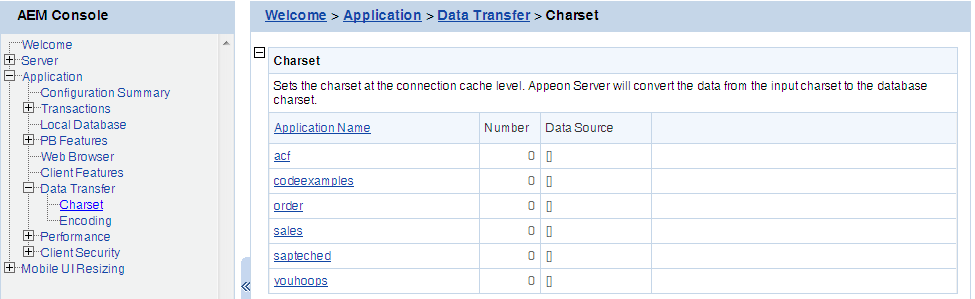
Step 1: Click an application in the Application Name column. The Configure Charset window opens.

Step 2: Click the Add Charset button. The Add Charset window opens.
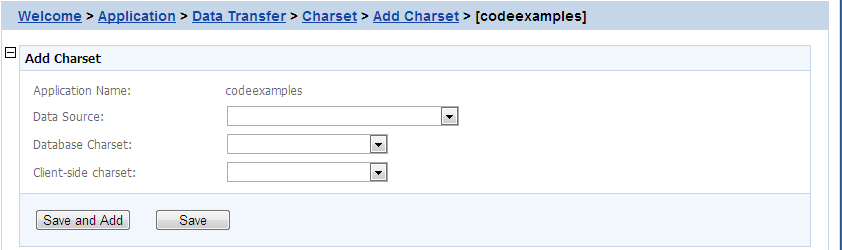
Step 3: Select the data source from the Data Source dropdown list.
Step 4: Select the database charset type from the Database Charset dropdown list. The Charset should be consistent with the Charset used in the database. This will not change the setting in the database.
Step 5: Select the input charset type from the Client-side Charset dropdown list. This setting should match the input Charset type at the client side.
Step 6: Click the Save button to confirm the configuration or Save and Add to add another one.
On the Charset page, click Update under Actions to update a Charset for a data source.
On the Charset page, click Delete under Actions to delete an unwanted Charset for a data source.
The following table lists all the Charset options provided in the "Database Charset" field and the "Client-side Charset" field, and provides a brief description of each Charset. If the actual database Charset or the input Charset is not provided as an option, you can use the following method to manually add the type as an option:
Step 1: Open the file constant.config in the directory %powerserver%\AEM\config\.
Step 2: Add the Charset type as an entry into the file, and save the file.
For example, if the Charset type that you want to add is "gbk", you can add a new line <charset name="gbk" value="gbk"></charset> in the file.
Step 3: Restart PowerServer and the "gbk" Charset will be added to the Charset lists.
The following table lists the character sets and code pages. The asterisk (*) at the last column indicates that Microsoft .NET Framework supports the code page, regardless of the platform.
Table 28. Charset and code pages
|
Page |
Charset |
Description |
Asterisk |
|---|---|---|---|
|
37 |
IBM037 |
IBM EBCDIC (US - Canada) |
|
|
437 |
IBM437 |
OEM US |
|
|
500 |
IBM500 |
IBM EBCDIC (International) |
|
|
708 |
ASMO-708 |
Arabic (ASMO 708) |
|
|
720 |
DOS-720 |
Arabic (DOS) |
|
|
737 |
ibm737 |
Greek (DOS) |
|
|
775 |
ibm775 |
Baltic (DOS) |
|
|
850 |
ibm850 |
Western European (DOS) |
|
|
852 |
ibm852 |
Central European (DOS) |
|
|
855 |
IBM855 |
OEM Cyrillic |
|
|
857 |
ibm857 |
Turkish (DOS) |
|
|
858 |
IBM00858 |
OEM Multi-Language Latin I |
|
|
860 |
IBM860 |
Portuguese (DOS) |
|
|
861 |
ibm861 |
Iceland (DOS) |
|
|
862 |
DOS-862 |
Hebrew (DOS) |
|
|
863 |
IBM863 |
Canadian French (DOS) |
|
|
864 |
IBM864 |
Arabic (864) |
|
|
865 |
IBM865 |
Northern European (DOS) |
|
|
866 |
cp866 |
Cyrillic (DOS) |
|
|
869 |
ibm869 |
Modern Greek (DOS) |
|
|
870 |
IBM870 |
IBM EBCDIC (Multi-Language Latin 2) |
|
|
874 |
windows-874 |
Thai (Windows) |
|
|
875 |
cp875 |
IBM EBCDIC (Modern Greek) |
|
|
932 |
shift_jis |
Japanese (Shift-JIS) |
|
|
936 |
gb2312 |
Simplified Chinese (GB2312) |
* |
|
949 |
ks_c_5601-1987 |
Korean |
|
|
950 |
big5 |
Traditional Chinese (Big5) |
|
|
1026 |
IBM1026 |
IBM EBCDIC (TurkishLatin 5) |
|
|
1047 |
IBM01047 |
IBM Latin 1 |
|
|
1140 |
IBM01140 |
IBM EBCDIC (US - Canada - Europe) |
|
|
1141 |
IBM01141 |
IBM EBCDIC (German - Europe) |
|
|
1142 |
IBM01142 |
IBM EBCDIC (Denmark - Norway - Europe) |
|
|
1143 |
IBM01143 |
IBM EBCDIC (Finland - Sweden - Europe) |
|
|
1144 |
IBM01144 |
IBM EBCDIC (Italy - Europe) |
|
|
1145 |
IBM01145 |
IBM EBCDIC (Spain- Europe) |
|
|
1146 |
IBM01146 |
IBM EBCDIC (U.K. - Europe) |
|
|
1147 |
IBM01147 |
IBM EBCDIC (France - Europe) |
|
|
1148 |
IBM01148 |
IBM EBCDIC (International - Europe) |
|
|
1149 |
IBM01149 |
IBM EBCDIC (Iceland - Europe) |
|
|
1200 |
utf-16 |
Unicode |
* |
|
1201 |
UnicodeFFFE |
Unicode (Big-Endian) |
* |
|
1250 |
windows-1250 |
Central Europe (Windows) |
|
|
1251 |
windows-1251 |
Cyrillic (Windows) |
|
|
1252 |
Windows-1252 |
Central Europe (Windows) |
* |
|
1253 |
windows-1253 |
Greek (Windows) |
|
|
1254 |
windows-1254 |
Turkish (Windows) |
|
|
1255 |
windows-1255 |
Hebrew (Windows) |
|
|
1256 |
windows-1256 |
Arabic (Windows) |
|
|
1257 |
windows-1257 |
Baltic (Windows) |
|
|
1258 |
windows-1258 |
Vietnamese (Windows) |
|
|
1361 |
Johab |
Korean (Johab) |
|
|
10000 |
macintosh |
Central Europe (Mac) |
|
|
10001 |
x-mac-japanese |
Japanese (Mac) |
|
|
10002 |
x-mac-chinesetrad |
Traditional Chinese (Mac) |
|
|
10003 |
x-mac-korean |
Korean (Mac) |
* |
|
10004 |
x-mac-arabic |
Arabic (Mac) |
|
|
10005 |
x-mac-hebrew |
Hebrew (Mac) |
|
|
10006 |
x-mac-greek |
Greek (Mac) |
|
|
10007 |
x-mac-cyrillic |
Cyrillic (Mac) |
|
|
10008 |
x-mac-chinesesimp |
Simplified Chinese (Mac) |
* |
|
10010 |
x-mac-romanian |
Romanian (Mac) |
|
|
10017 |
x-mac-ukrainian |
Ukrainian (Mac) |
|
|
10021 |
x-mac-thai |
Thai (Mac) |
|
|
10029 |
x-mac-ce |
Central Europe (Mac) |
|
|
10079 |
x-mac-icelandic |
Iceland (Mac) |
|
|
10081 |
x-mac-turkish |
Turkish (Mac) |
|
|
10082 |
x-mac-croatian |
Croatian (Mac) |
|
|
20000 |
x-Chinese-CNS |
Traditional Chinese (CNS) |
|
|
20001 |
x-cp20001 |
TCA Taiwan |
|
|
20002 |
x-Chinese-Eten |
Traditional Chinese (Eten) |
|
|
20003 |
x-cp20003 |
IBM5550 Taiwan |
|
|
20004 |
x-cp20004 |
TeleText Taiwan |
|
|
20005 |
x-cp20005 |
Wang Taiwan |
|
|
20105 |
x-IA5 |
Central Europe (IA5) |
|
|
20106 |
x-IA5-German |
Germany (IA5) |
|
|
20107 |
x-IA5-Swedish |
Swedish (IA5) |
|
|
20108 |
x-IA5-Norwegian |
Norwegian (IA5) |
|
|
20127 |
us-ascii |
US-ASCII |
* |
|
20261 |
x-cp20261 |
T.61 |
|
|
20269 |
x-cp20269 |
ISO-6937 |
|
|
20273 |
IBM273 |
IBM EBCDIC (Germany) |
|
|
20277 |
IBM277 |
IBM EBCDIC (Denmark - Norwegian) |
|
|
20278 |
IBM278 |
IBM EBCDIC (Finland- Swedish) |
|
|
20280 |
IBM280 |
IBM EBCDIC (Italy) |
|
|
20284 |
IBM284 |
IBM EBCDIC (Spanish) |
|
|
20285 |
IBM285 |
IBM EBCDIC (U.K.) |
|
|
20290 |
IBM290 |
IBM EBCDIC (Japanese Katakana) |
|
|
20297 |
IBM297 |
IBM EBCDIC (France) |
|
|
20420 |
IBM420 |
IBM EBCDIC (Arabic) |
|
|
20423 |
IBM423 |
IBM EBCDIC (Greek) |
|
|
20424 |
IBM424 |
IBM EBCDIC (Hebrew) |
|
|
20833 |
x-EBCDIC-KoreanExtended |
IBM EBCDIC (Korean Extension) |
|
|
20838 |
IBM-Thai |
IBM EBCDIC (Thai) |
|
|
20866 |
koi8-r |
Cyrillic (KOI8-R) |
|
|
20871 |
IBM871 |
IBM EBCDIC (Iceland) |
|
|
20880 |
IBM880 |
IBM EBCDIC (Cyrillic Russian) |
|
|
20905 |
IBM905 |
IBM EBCDIC (Turkish) |
|
|
20924 |
IBM00924 |
IBM Latin 1 |
|
|
20932 |
EUC-JP |
Japanese (JIS 0208-1990 and 0212-1990) |
|
|
20936 |
x-cp20936 |
Simplified Chinese (GB2312-80) |
* |
|
20949 |
x-cp20949 |
Korean Wansung |
* |
|
21025 |
cp1025 |
IBM EBCDIC (Cyrillic Serbian - Bulgarian) |
|
|
21866 |
koi8-u |
Cyrillic (KOI8-U) |
|
|
28591 |
iso-8859-1 |
Central Europe (ISO) |
* |
|
28592 |
iso-8859-2 |
Central Europe (ISO) |
|
|
28593 |
iso-8859-3 |
Latin 3 (ISO) |
|
|
28594 |
iso-8859-4 |
Baltic (ISO) |
|
|
28595 |
iso-8859-5 |
Cyrillic (ISO) |
|
|
28596 |
iso-8859-6 |
Arabic (ISO) |
|
|
28597 |
iso-8859-7 |
Greek (ISO) |
|
|
28598 |
iso-8859-8 |
Hebrew (ISO-Visual) |
* |
|
28599 |
iso-8859-9 |
Turkish (ISO) |
|
|
28603 |
iso-8859-13 |
Estonian (ISO) |
|
|
28605 |
iso-8859-15 |
Latin 9 (ISO) |
|
|
29001 |
x-Europa |
Europa |
|
|
38598 |
iso-8859-8-i |
Hebrew (ISO-Logical) |
* |
|
50220 |
iso-2022-jp |
Japanese (JIS) |
* |
|
50221 |
csISO2022JP |
Japanese (JIS- 1 byte Kana) |
* |
|
50222 |
iso-2022-jp |
Japanese (JIS- 1 byte Kana - SO/SI) |
* |
|
50225 |
iso-2022-kr |
Korean (ISO) |
* |
|
50227 |
x-cp50227 |
Simplified Chinese (ISO-2022) |
* |
|
51932 |
euc-jp |
Japanese (EUC) |
* |
|
51936 |
EUC-CN |
Simplified Chinese (EUC) |
* |
|
51949 |
euc-kr |
Korean (EUC) |
* |
|
52936 |
hz-gb-2312 |
Simplified Chinese (HZ) |
* |
|
54936 |
GB18030 |
Simplified Chinese (GB18030) |
* |
|
57002 |
x-iscii-de |
ISCII Sanskrit |
* |
|
57003 |
x-iscii-be |
ISCII Bengalese |
* |
|
57004 |
x-iscii-ta |
ISCII Tamil |
* |
|
57005 |
x-iscii-te |
ISCII Telugu |
* |
|
57006 |
x-iscii-as |
ISCII Assamese |
* |
|
57007 |
x-iscii-or |
ISCII Oriya |
* |
|
57008 |
x-iscii-ka |
ISCII Kannada |
* |
|
57009 |
x-iscii-ma |
ISCII Malayalam |
* |
|
57010 |
x-iscii-gu |
ISCII Gujarat |
* |
|
57011 |
x-iscii-pa |
ISCII Punjab |
* |
|
65000 |
utf-7 |
Unicode (UTF-7) |
* |
|
65001 |
utf-8 |
Unicode (UTF-8) |
* |
|
65005 |
utf-32 |
Unicode (UTF-32) |
* |
|
65006 |
utf-32BE |
Unicode (UTF-32 Big-Endian) |
* |
Encoding specifies the encoding format for data transferred between the clients and the server. The transfer speed varies when the encoding format changes.
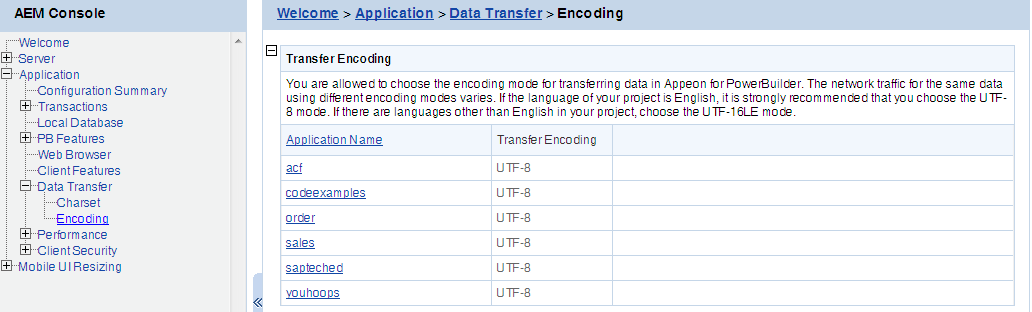
If the language of the application is pure English, select UTF-8; otherwise, select UTF-16LE.

