About this chapter
This chapter describes how to use the Data Pipeline painter to create data pipelines, which let you reproduce database data in various ways.
The Data Pipeline painter gives you the ability to reproduce data quickly within a database, across databases, or even across DBMSs. To do that, you create a data pipeline which, when executed, pipes the data as specified in the definition of the data pipeline.
What you can do
With the Data Pipeline painter, you can perform some tasks that would otherwise be very time consuming. For example, you can:
-
Pipe data (and extended attributes) from one or more tables to a table in the same DBMS or a different DBMS
-
Pipe an entire database, a table at a time, to another DBMS (and if needed, pipe the database's extended attribute system tables)
-
Create a table with the same design as an existing table but with no data
-
Pipe corporate data from a database server to a SQL Anywhere database on your computer so you can work on the data and report on it without needing access to the network
-
Upload local data that changes daily to a corporate database
-
Create a new table when a change (such as allowing or disallowing NULLs or changing primary key or index assignments) is disallowed in the Database painter
Piping data in applications
You can also create applications that pipe data. For more information, see the section called “Piping Data Between Data Sources” in Application Techniques.
Source and destination databases
You can use the Data Pipeline painter to pipe data from one or more tables in a source database to one table in a destination database.
You can pipe all data or selected data in one or more tables. For example, you can pipe a few columns of data from one table or data selected from a multitable join. You can also pipe from a view or a stored procedure result set to a table.
When you pipe data, the data in the source database remains in the source database and is reproduced in a new or existing table in the destination database.
Although the source and destination can be the same database, they are usually different ones, and they can even have different DBMSs. For example, you can pipe data from an Adaptive Server Enterprise database to a SQL Anywhere database on your computer.
When you use the Data Pipeline painter to create a pipeline, you define the:
-
Source database
-
Destination database
-
Source of data
-
Pipeline operation
-
Destination table
After you create a pipeline, you can execute it immediately. If you want, you can also save it as a named object to use and reuse. Saving a pipeline enables you to pipe the data that might have changed since the last pipeline execution or to pipe the data to other databases later.
Datatype support
Each DBMS supports certain datatypes. When you pipe data from one DBMS to another, PowerBuilder makes a best guess at the appropriate destination datatypes. You can correct PowerBuilder's best guess in your pipeline definition as needed.
The Data Pipeline painter supports the piping of columns of any datatype, including columns with blob data. For information about piping a column that has a blob datatype, see Piping blob data.
The first time PowerBuilder connects to a database, it creates five system tables called the extended attribute system tables. These system tables initially contain default extended attribute information for tables and columns. In PowerBuilder, you can create extended attribute definitions such as column headers and labels, edit styles, display formats, and validation rules.
For more information about the extended attribute system tables, see Appendix A, The Extended Attribute System Tables.
Piping extended attributes automatically
When you pipe data, you can specify that you want to pipe the extended attributes associated with the columns you are piping. You do this by selecting the Extended Attributes check box in the Data Pipeline painter workspace:
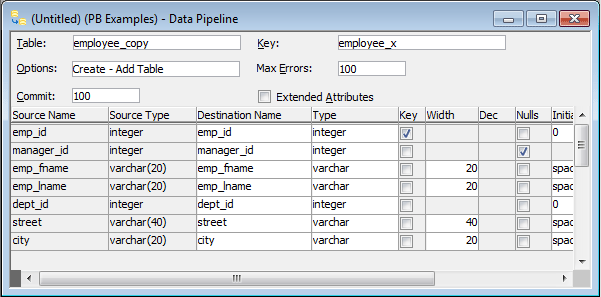
When the Extended Attributes check box is selected, the extended attributes associated with the source database's selected columns automatically go into the extended attribute system tables of the destination database, with one exception. When you pipe a column that has an edit style, display format, or validation rule associated with it, the style, rule, or format is not piped if one with the same name exists in the extended attribute system tables of the destination database. In this situation, the column uses the style, rule, or format already present in the destination database.
For example, for the Phone column in the Employee table, the display format with the name Phone_format would be piped unless a display format with the name Phone_format already exists in the destination database. If such a display format exists, the Phone column would use the Phone_format display format in the destination database.
Piping the extended attribute system tables
Selecting the Extended Attributes check box never results in the piping of named display formats, edit styles, and validation rules that are stored in the extended attribute system tables but are not associated with columns in tables you are piping. If you want such extended attribute definitions from one database to exist in another database, you can pipe the appropriate extended attribute system table or a selected row or rows from the table.
Piping an entire database
If you want to reproduce an entire database, you can pipe all database tables and extended attribute system tables, one table at a time.
You have a number of choices when creating a data pipeline. This section leads you through them.
To create a data pipeline:
-
Click the New button in the PowerBar and then select the Database tab page.
-
Select Data Pipeline and click OK.
The New Data Pipeline dialog box displays.
The Source Connection and Destination Connection boxes display database profiles that have been defined. The last database you connected to is selected as the source. The first database on the destination list is selected as the destination.
If you do not see the connections you need
To create a pipeline, the databases you want to use for your source and destination must each have a database profile defined. If you do not see profiles for the databases you want to use, select Cancel in the New Data Pipeline dialog box and then define those profiles. For information about defining profiles, see Changing the destination and source databases.
-
Select a data source.
The data source determines how PowerBuilder retrieves data when you execute a pipeline:
Data source
Use it if
Quick Select
The data is from tables that have a primary/foreign key relationship and you need only to sort and limit data
SQL Select
You want more control over the SQL SELECT statement generated for the data source or your data is from tables that are not connected through a key
Query
The data has been defined as a query
Stored Procedure
The data is defined in a stored procedure
-
Select the source and destination connections and click OK.
-
Define the data to pipe.
How you do this depends on what data source you chose in step 3, and is similar to the process used to define a data source for a DataWindow object. For complete information about using each data source and defining the data, see Defining DataWindow Objects.
When you finish defining the data to pipe, the Data Pipeline painter workspace displays the pipeline definition, which includes a pipeline operation, a check box for specifying whether to pipe extended attributes, and source and destination items.
The pipeline definition is PowerBuilder's best guess based on the source data you specified.
-
Modify the pipeline definition as needed.
For information, see Modifying the data pipeline definition.
-
(Optional) Modify the source data as needed. To do so, click the Data button in the PainterBar, or select Design>Edit Data Source from the menu bar.
For information about working in the Select painter, see Defining DataWindow Objects.
When you return to the Data Pipeline painter workspace, PowerBuilder reminds you that the pipeline definition will change. Click OK to accept the definition change.
If you want to try the pipeline now, click the Execute button or select Design>Execute from the menu bar.
PowerBuilder retrieves the source data and executes the pipeline. If you specified retrieval arguments in the Select painter, PowerBuilder first prompts you to supply them.
At runtime, the number of rows read and written, the elapsed execution time, and the number of errors display in MicroHelp. You can stop execution yourself or PowerBuilder might stop execution if errors occur.
For information about execution and how rows are committed to the destination table, see When execution stops.
-
Save the pipeline definition if appropriate.
For information, see Saving a pipeline.
Seeing the results of piping data
You can see the results of piping data by connecting to the destination database and opening the destination table.
After you create a pipeline definition, you can modify it in a variety of ways. The changes you make depend on what pipeline operation you select, the destination DBMS, and what you are trying to accomplish by executing the pipeline.
The following table lists properties you can modify that apply to the destination table. These properties display at the top of the Data Pipeline painter workspace.
|
Item |
Description |
Default |
How to edit |
|---|---|---|---|
|
Table |
Name of the destination table. |
If source and destination are different, name of first table specified in the source data or name of the stored procedure. If the same, _copy is appended. |
For Create or Replace, enter a name. For Refresh, Append, or Update, select a name from the drop-down list. |
|
Options |
Pipeline operation: Create, Replace, Refresh, Append, or Update. |
Create - Add Table. |
Select an option from the drop-down list. See The following table. |
|
Commit |
Number of rows piped to the destination database before PowerBuilder commits the rows to the database. |
100 rows. |
Select a number, All, or None from the drop-down list. |
|
Key |
Key name for the table in the destination database. |
If the source is only one table, the table name is followed by _x. |
(Create or Replace only) Enter a name. |
|
Max Errors |
Number of errors allowed before the pipeline stops. |
100 errors. |
Select a number or No Limit from the drop-down list. |
|
Extended Attributes |
(Create and Replace only) Specifies whether or not the extended attributes of the selected source columns are piped to the extended attribute system tables of the destination database. |
Not checked. |
Click the check box. |
The following table lists properties that you can modify that apply to the destination table's columns and keys. These properties display under the properties that apply to the table itself and most can be modified only for the Create and Replace pipeline operations.
Column names and datatypes that cannot be modified
You cannot modify the source column names and datatypes that display at the left of the workspace.
|
Item |
Description |
Default |
How to edit |
|---|---|---|---|
|
Destination Name |
Column name |
Source column name. |
Enter a name. |
|
Type |
Column datatype |
If the DBMS is unchanged, source column datatype. If the DBMS is different, a best-guess datatype. |
Select a type from the drop-down list. |
|
Key |
Whether the column is a key column (check means yes) |
Source table's key columns (if the source is only one table and all key columns were selected). |
Select or clear check boxes. |
|
Width |
Column width |
Source column width. |
Enter a number. |
|
Dec |
Decimal places for the column |
Source column decimal places. |
Enter a number. |
|
Nulls |
Whether NULL is allowed for the column (check means yes) |
Source column value. |
Select or clear check boxes. |
|
Initial Value |
Column initial value |
Source column initial value. (If no initial value, character columns default to spaces and numeric columns default to 0.) |
Select an initial value from the drop-down list. |
|
Default Value |
Column default value |
None. Default values stored in the source database are not piped to the destination database. |
Select a default value from the drop-down list or enter a default value. Keyword values depend on destination DBMS. |
When PowerBuilder pipes data, what happens in the destination database depends on which pipeline operation you choose in the Options drop-down list at the top of the workspace.
|
Pipeline operation |
Effect on destination database |
|---|---|
|
Create - Add Table |
A new table is created and rows selected from the source tables are inserted. If a table with the specified name already exists in the destination database, a message displays and you must select another option or change the table name. |
|
Replace - Drop/Add Table |
An existing table with the specified table name is dropped, a new table is created, and rows selected from the source tables are inserted. If no table exists with the specified name, a table is created. |
|
Refresh - Delete/Insert Rows |
All rows of data in an existing table are deleted, and rows selected from the source tables are inserted. |
|
Append - Insert Rows |
All rows of data in an existing table are preserved, and new rows selected from the source tables are inserted. |
|
Update - Update/Insert Rows |
Rows in an existing table that match the key criteria values in the rows selected from the source tables are updated, and rows that do not match the key criteria values are inserted. |
The modifications you can make in the workspace depend on the pipeline operation you have chosen.
When using Create or Replace
When you select the Create - Add Table option (the default) or the Replace - Drop/Add Table option, you can:
-
Change the destination table definition.
-
Follow the rules of the destination DBMS.
-
Specify or clear a key name and/or key columns.
-
Specify key columns by selecting one or more check boxes to define a unique identifier for rows. Neither a key name nor key columns are required.
-
Allow or disallow NULLs for a column.
-
If NULL is allowed, no initial value is allowed. If NULL is not allowed, an initial value is required. The words spaces (a string filled with spaces) and today (today's date) are initial value keywords.
-
Modify the Commit and Max Errors values.
-
Specify an initial value and a default value.
If you have specified key columns and a key name and if the destination DBMS supports primary keys, the Data Pipeline painter creates a primary key for the destination table. If the destination DBMS does not support primary keys, a unique index is created.
For Oracle databases
PowerBuilder generates a unique index for Oracle databases.
If you try to use the Create option, but a table with the specified name already exists in the destination database, PowerBuilder tells you, and you must select another option or change the table name.
When you use the Replace option, PowerBuilder warns you that you are deleting a table, and you can choose another option if needed.
When using Refresh and Append
For the Refresh - Delete/Insert Rows or Append - Insert Rows options, the destination table must already exist. You can:
-
Select an existing table from the Table drop-down list.
-
Modify the Commit and Max Errors values.
-
Change the initial value for a column.
When using Update
For the Update - Update/Insert Rows option, the destination table must already exist. You can:
-
Select an existing table from the Table drop-down list.
-
Modify the Commit and Max Errors values.
-
Change the Key columns in the destination table's primary key or unique index, depending on what the DBMS supports. Key columns must be selected; the key determines the UPDATE statement's WHERE clause.
-
Change the initial value for a column.
Bind variables and the Update option
If the destination database supports bind variables, the Update option takes advantage of them to optimize pipeline execution.
Execution of a pipeline can stop for any of these reasons:
-
You click the Cancel button
-
During the execution of a pipeline, the Execute button in the PainterBar changes to a Cancel button.
-
The error limit is reached
If there are rows that cannot be piped to the destination table for some reason, those error rows display once execution stops. You can correct error rows or return to the workspace to change the pipeline definition and then execute it again. For information, see Correcting pipeline errors.
When rows are piped to the destination table, they are first inserted and then either committed or rolled back. Whether rows are committed depends on:
-
What the Commit and Max Errors values are
-
When errors occur during execution
-
Whether you click the Cancel button or PowerBuilder stops execution
When you stop execution
When you click Cancel, if the Commit value is a number, every row that was piped is committed. If the Commit value is All or None, every row that was piped is rolled back.
For example, if you click the Cancel button when the 24th row is piped and the Commit value is 20, then:
-
20 rows are piped and committed.
-
3 rows are piped and committed.
-
Piping stops.
If the Commit value is All or None, 23 rows are rolled back.
When PowerBuilder stops execution
PowerBuilder stops execution if the error limit is reached. The following table shows how the Commit and Max Errors values affect the number of rows that are piped and committed.
|
Commit value |
Max Errors value |
Result |
|---|---|---|
|
A number n |
No limit or a number m |
Rows are piped and committed n rows at a time until the Max Errors value is reached. |
|
All or None |
No limit |
Every row that pipes without error is committed. |
|
All or None |
A number n |
If the number of errors is less than n, all rows are committed. If the number of errors is equal to n, every row that was piped is rolled back. No changes are made. |
For example, if an error occurs when the 24th row is piped and the Commit value is 10 and the Max Errors value is 1, then:
-
10 rows are piped and committed.
-
10 rows are piped and committed.
-
3 rows are piped and committed.
-
Piping stops.
If the Commit value is All or None, 23 rows are rolled back.
About transactions
A transaction is a logical unit of work done by a DBMS, within which either all the work in the unit must be completed or none of the work in the unit must be completed. If the destination DBMS does not support transactions or is not in the scope of a transaction, each row that is inserted or updated is committed.
About the All and None commit values
In the Data Pipeline painter, the Commit values All and None have the same meaning.
The None commit value is most useful at runtime. For example, some PowerBuilder applications require either all piped rows to be committed or no piped rows to be committed if an error occurs. Specifying None allows the application to control the committing and rolling back of piped rows by means of explicit transaction processing, such as the issuing of commits and rollbacks in pipeline scripts using COMMIT and ROLLBACK statements.
Blob data is data that is a binary large-object such as a Microsoft Word document or an Excel spreadsheet. A data pipeline can pipe columns containing blob data.
The name of the datatype that supports blob data varies by DBMS. The following table shows some examples.
|
DBMS |
Datatypes that support blob data |
|---|---|
|
SAP SQL Anywhere |
LONG BINARY, LONG VARCHAR (if more than 32 KB) |
|
SAP Adaptive Server Enterprise |
IMAGE, TEXT |
|
Microsoft SQL Server |
IMAGE, TEXT |
|
Oracle |
RAW, LONG RAW |
|
Informix |
BYTE, TEXT |
For information about the datatype that supports blob data in your DBMS, see your DBMS documentation.
Adding blob columns to a pipeline definition
When you select data to pipe, you cannot select a blob column as part of the data source because blobs cannot be handled in a SELECT statement. After the pipeline definition is created, you add blob columns, one at a time, to the definition.
To add a blob column to a pipeline definition
-
Select Design>Database Blob from the menu bar.
If the Database Blob menu item is disabled
The Database Blob menu item is disabled if the pipeline definition does not contain a unique key for at least one source table, or if the pipeline operation is Refresh, Append, or Update and the destination table has no blob columns.
The Database Binary/Text Large Object dialog box displays. The Table box has a drop-down list of tables in the pipeline source that have a primary key and contain blob columns.
-
In the Table box, select the table that contains the blob column you want to add to the pipeline definition.
For example, in the PB Demo DB, the ole table contains a blob column named Object with the large binary datatype.
-
In the Large Binary/Text Column box, select a column that has a blob datatype.
-
In the Destination Column box, change the name of the destination column for the blob if you want to.
-
If you want to add the column and see changes you make without closing the dialog box, click Apply after each change.
When you have specified the blob source and destination as needed, click OK.
To edit the source or destination name of the blob column in the pipeline definition
-
Display the blob column's pop-up menu and select Properties.
To delete a blob column from the pipeline definition
-
Display the blob column's pop-up menu and select Clear.
Executing a pipeline with blob columns
After you have completed the pipeline definition by adding one or more blob columns, you can execute the pipeline. When you do, rows are piped a block at a time, depending on the Commit value. For a given block, Row 1 is inserted, then Row 1 is updated with Blob 1, then Row 1 is updated with Blob 2, and so on. Then Row 2 is inserted, and so on until the block is complete.
If a row is not successfully piped, the blob is not piped. Blob errors display, but the blob itself does not display. When you correct a row and execute the pipeline, the pipeline pipes the blob.
Changing the destination
When you create a pipeline, you can change the destination database. If you want to pipe the same data to more than one destination, you can change the destination database again and re-execute.
To change the destination database
-
Click the Destination button in the PainterBar, or select File>Destination Connect from the menu bar.
Changing the source
Normally you would not change the source database, because your pipeline definition is dependent on it, but if you need to (perhaps because you are no longer connected to that source), you can.
Source changes when active profile changes
When you open a pipeline in the Data Pipeline painter, the source database becomes the active connection. If you change the active connection in the Database painter when the Data Pipeline painter is open, the source database in the Data Pipeline painter changes to the new active connection automatically.
Working with database profiles
At any time in the Data Pipeline painter, you can edit an existing database profile or create a new one.
To edit or create a database profile
-
Click the Database Profile button in the PainterBar and then click the Edit button or the New button.
For information about how to edit or define a database profile, see the section called “Using database profiles” in Connecting to Your Database.
If the pipeline cannot pipe certain rows to the destination table for some reason, PowerBuilder displays the following information for the error rows:
-
Name of the table in the destination database
-
Pipeline operation you chose in the Option box
-
Error messages to identify the problem with each row
-
Data values in the error rows
-
Source and destination column information
What you can do
You can correct the error rows by changing one or more of their column values so the destination table will accept them, or you can ignore the error rows and return to the Data Pipeline painter workspace. If you return to the workspace, you cannot redisplay the error rows without re-executing the pipeline.
Before you return to the workspace
You might want to print the list of errors or save them in a file. Select File>Print or File>Save As from the menu bar.
To return to the Data Pipeline painter workspace without correcting errors:
-
Click the Design button.
To correct pipeline errors:
-
Change data values for the appropriate columns in the error rows.
-
Click the Update DB button, or select Design>Update Database from the menu bar.
PowerBuilder pipes rows in which errors were corrected to the destination table and displays any remaining errors.
-
Repeat steps 1 and 2 until all errors are corrected.
The Data Pipeline painter workspace displays.
Viewing an error message
Sometimes you cannot see an entire error message because the column is not wide enough. Move the pointer to the error message and press the Right Arrow key to scroll through it. You can also drag the Error Message column border to the width needed.
Making the error messages shorter
For ODBC data sources, you can set the MsgTerse database parameter in the destination database profile to make the error messages shorter. If you type MsgTerse = 'Yes', then the SQLSTATE error number does not display. For more information on the MsgTerse parameter, see the section called “MsgTerse” in Connection Reference.
When you have generated a pipeline definition in the Data Pipeline painter workspace, you should save the pipeline. You can then reuse it later.
For a new pipeline
When you save a pipeline for the first time, you must specify a name. The name can be any valid identifier with up to 80 characters. A common convention is to prefix the name with the string pipe_. You can also specify the library in which the pipeline is saved.
If you save a pipeline, you can modify and execute it any time. You can also pipe data that might have changed since the last pipeline execution or pipe data to other databases.
To use an existing pipeline:
-
Click the Open button in the PowerBar.
-
In the Open dialog box, select the Pipelines object type in the Object Type drop-down list, select the library, select the pipeline you want to execute, and click OK.
In the Open dialog box, pipelines in the selected libraries are listed. If you do not see the pipeline you want, close the dialog box and add the library you need to the target's library search path.
If you want to change the pipeline operation, select a new option from the Options drop-down list in the workspace.
-
Modify the pipeline definition as needed.
-
Execute and/or save the pipeline.
Updating data in a destination table
You might want to pipe data and then update the data often.
To update a destination table:
-
Click the Pipeline button, select an existing pipeline that you executed before, and click OK.
The pipeline definition displays. Since this pipeline has been executed before, the table exists in the destination database.
-
Select the Update option in the pipeline definition.
-
Execute the pipeline.
The destination table is updated with current data from the source database.
Reproducing a table definition with no data
You can force a pipeline to create a table definition and not pipe data. To do this, you must use Quick Select, SQL Select, or Query as the data source. It is easiest to do it using SQL Select.
To reproduce a table definition with no data:
-
Click the Pipeline button, click New, select SQL Select as the data source and specify the source and destination databases, and click OK.
-
In the Select painter, open the table you want to reproduce and select all columns.
-
On the Where tab page, type an expression that will never evaluate to true, such as 1 = 2.
-
Click the SQL Select button to create the pipeline definition.
-
Select the Extended Attributes check box.
-
Click the Execute button to execute the pipeline.
The table definition is piped to the destination database, but no rows of data are piped. You can open the new table in the Database painter and then click the Grid, Table, or Freeform button to view the data. As specified, there is no data.
If you use a data source other than SQL Select, you can follow the previous procedure, but you need to edit the data source of the pipeline to open the Select painter in step 2.
Piping a table to many databases
In the Data Pipeline painter workspace, you can execute a pipeline many times with a different destination database each time.
