About this chapter
This chapter tells you how you can use a Pipeline object in your application to pipe data from one or more source tables to a new or existing destination table.
Sample applications
This chapter uses a simple order entry application to illustrate the use of a data pipeline. To see working examples using data pipelines, look at the examples in the Data Pipeline category in the Code Examples sample application.
For information on how to use the sample applications, see Using Sample Applications.
PowerBuilder provides a feature called the data pipeline that you can use to migrate data between database tables. This feature makes it possible to copy rows from one or more source tables to a new or existing destination table -- either within a database, or across databases, or even across DBMSs.
Two ways to use data pipelines
You can take advantage of data pipelines in two different ways:
-
As a utility service for developers
While working in the PowerBuilder development environment, you might occasionally want to migrate data for logistical reasons (such as to create a small test table from a large production table). In this case, you can use the Data Pipeline painter interactively to perform the migration immediately.
For more information on using the Data Pipeline painter this way, see the section called “Working with Data Pipelines” in Users Guide.
-
To implement data migration capabilities in an application
If you are building an application whose requirements call for migrating data between tables, you can design an appropriate data pipeline in the Data Pipeline painter, save it, and then enable users to execute it from within the application.
This technique can be useful in many different situations, such as: when you want the application to download local copies of tables from a database server to a remote user, or when you want it to roll up data from individual transaction tables to a master transaction table.
Walking through the basic steps
If you determine that you need to use a data pipeline in your application, you must determine what steps this involves. At the most general level, there are five basic steps that you typically have to perform.
To pipe data in an application:
-
Build the objects you need.
-
Perform some initial housekeeping.
-
Start the pipeline.
-
Handle row errors.
-
Perform some final housekeeping.
The remainder of this chapter gives you the details of each step.
To implement data piping in an application, you need to build a few different objects:
-
A Pipeline object
-
A supporting user object
-
A window
You must build a Pipeline object to specify the data definition and access aspects of the pipeline that you want your application to execute. Use the Data Pipeline painter in PowerBuilder to create this object and define the characteristics you want it to have.
Characteristics to define
Among the characteristics you can define in the Data Pipeline painter are:
-
The source tables to access and the data to retrieve from them (you can also access database stored procedures as the data source)
-
The destination table to which you want that data piped
-
The piping operation to perform (create, replace, refresh, append, or update)
-
The frequency of commits during the piping operation (after every n rows are piped, or after all rows are piped, or not at all -- if you plan to code your own commit logic)
-
The number of errors to allow before the piping operation is terminated
-
Whether or not to pipe extended attributes to the destination database (from the PowerBuilder repository in the source database)
For full details on using the Data Pipeline painter to build your Pipeline object, see the section called “Working with Data Pipelines” in Users Guide.
Example
Here is an example of how you would use the Data Pipeline painter to define a Pipeline object named pipe_sales_extract1 (one of two Pipeline objects employed by the w_sales_extract window in a sample order entry application).
The source data to pipe
This Pipeline object joins two tables (Sales_rep and Sales_summary) from the company's sales database to provide the source data to be piped. It retrieves just the rows from a particular quarter of the year (which the application must specify by supplying a value for the retrieval argument named quarter):
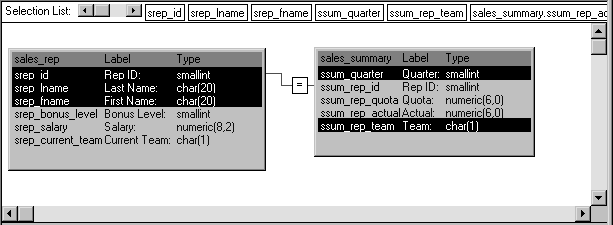
Notice that this Pipeline object also indicates specific columns to be piped from each source table (srep_id, srep_lname, and srep_fname from the Sales_rep table, as well as ssum_quarter and ssum_rep_team from the Sales_summary table). In addition, it defines a computed column to be calculated and piped. This computed column subtracts the ssum_rep_quota column of the Sales_summary table from the ssum_rep_actual column:
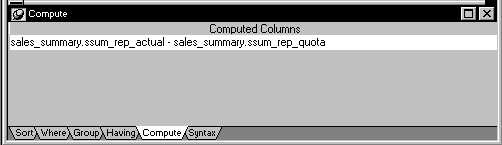
How to pipe the data
The details of how pipe_sales_extract1 is to pipe its source data are specified here:
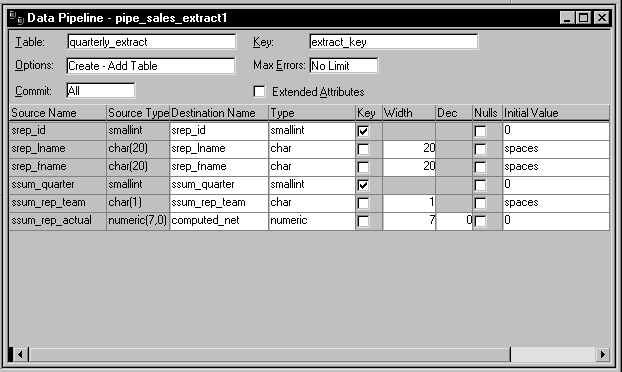
Notice that this Pipeline object is defined to create a new destination table named Quarterly_extract. A little later you will learn how the application specifies the destination database in which to put this table (as well as how it specifies the source database in which to look for the source tables).
Also notice that:
-
A commit will be performed only after all appropriate rows have been piped (which means that if the pipeline's execution is terminated early, all changes to the Quarterly_extract table will be rolled back).
-
No error limit is to be imposed by the application, so any number of rows can be in error without causing the pipeline's execution to terminate early.
-
No extended attributes are to be piped to the destination database.
-
The primary key of the Quarterly_extract table is to consist of the srep_id column and the ssum_quarter column.
-
The computed column that the application is to create in the Quarterly_extract table is to be named computed_net.
So far you have seen how your Pipeline object defines the details of the data and access for a pipeline, but a Pipeline object does not include the logistical supports -- properties, events, and functions -- that an application requires to handle pipeline execution and control.
About the Pipeline system object
To provide these logistical supports, you must build an appropriate user object inherited from the PowerBuilder Pipeline system object. The following table shows some of the system object's properties, events, and functions that enable your application to manage a Pipeline object at runtime.
|
Properties |
Events |
Functions |
|---|---|---|
|
DataObject RowsRead RowsWritten RowsInError Syntax |
PipeStart PipeMeter PipeEnd |
Start Repair Cancel |
A little later in this chapter you will learn how to use most of these properties, events, and functions in your application.
To build the supporting user object for a pipeline:
-
Select Standard Class from the PB Object tab of the New dialog box.
The Select Standard Class Type dialog box displays, prompting you to specify the name of the PowerBuilder system object (class) from which you want to inherit your new user object:

-
Select pipeline and click OK.
-
Make any changes you want to the user object (although none are required). This might involve coding events, functions, or variables for use in your application.
To learn about one particularly useful specialization you can make to your user object, see Monitoring pipeline progress.
Planning ahead for reuse
As you work on your user object, keep in mind that it can be reused in the future to support any other pipelines you want to execute. It is not automatically tied in any way to a particular Pipeline object you have built in the Data Pipeline painter.
To take advantage of this flexibility, make sure that the events, functions, and variables you code in the user object are generic enough to accommodate any Pipeline object.
-
Save the user object.
For more information on working with the User Object painter, see the section called “Working with User Objects” in Users Guide.
One other object you need when piping data in your application is a window. You use this window to provide a user interface to the pipeline, enabling people to interact with it in one or more ways. These include:
-
Starting the pipeline's execution
-
Displaying and repairing any errors that occur
-
Canceling the pipeline's execution if necessary
Required features for your window
When you build your window, you must include a DataWindow control that the pipeline itself can use to display error rows (that is, rows it cannot pipe to the destination table for some reason). You do not have to associate a DataWindow object with this DataWindow control -- the pipeline provides one of its own at runtime.
To learn how to work with this DataWindow control in your application, see Starting the pipeline and Handling row errors.
Optional features for your window
Other than including the required DataWindow control, you can design the window as you like. You will typically want to include various other controls, such as:
-
CommandButton or PictureButton controls to let the user initiate actions (such as starting, repairing, or canceling the pipeline)
-
StaticText controls to display pipeline status information
-
Additional DataWindow controls to display the contents of the source and/or destination tables
If you need assistance with building a window, see the section called “Building a new window” in Users Guide.
Example
The following window handles the user-interface aspect of the data piping in the order entry application. This window is named w_sales_extract:
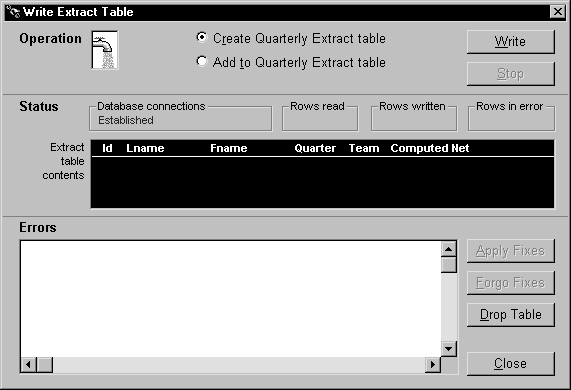
Several of the controls in this window are used to implement particular pipeline-related capabilities. The following table provides more information about them.
|
Control type |
Control name |
Purpose |
|---|---|---|
|
RadioButton |
rb_create |
Selects pipe_sales_extract1 as the Pipeline object to execute |
|
rb_insert |
Selects pipe_sales_extract2 as the Pipeline object to execute |
|
|
CommandButton |
cb_write |
Starts execution of the selected pipeline |
|
cb_stop |
Cancels pipeline execution or applying of row repairs |
|
|
cb_applyfixes |
Applies row repairs made by the user (in the dw_pipe_errors DataWindow control) to the destination table |
|
|
cb_forgofixes |
Clears all error rows from the dw_pipe_errors DataWindow control (for use when the user decides not to make repairs) |
|
|
DataWindow |
dw_review_extract |
Displays the current contents of the destination table (Quarterly_extract) |
|
dw_pipe_errors |
(Required) Used by the pipeline itself to automatically display the PowerBuilder pipeline-error DataWindow (which lists rows that cannot be piped due to some error) |
|
|
StaticText |
st_status_read |
Displays the count of rows that the pipeline reads from the source tables |
|
st_status_written |
Displays the count of rows that the pipeline writes to the destination table or places in dw_pipe_errors |
|
|
st_status_error |
Displays the count of rows that the pipeline places in dw_pipe_errors (because they are in error) |
Now that you have the basic objects you need, you are ready to start writing code to make your pipeline work in the application. To begin, you must take care of some setup chores that will prepare the application to handle pipeline execution.
To get the application ready for pipeline execution:
-
Connect to the source and destination databases for the pipeline.
To do this, write the usual connection code in an appropriate script. Just make sure you use one Transaction object when connecting to the source database and a different Transaction object when connecting to the destination database (even if it is the same database).
For details on connecting to a database, see Using Transaction Objects.
-
Create an instance of your supporting user object (so that the application can use its properties, events, and functions).
To do this, first declare a variable whose type is that user object. Then, in an appropriate script, code the CREATE statement to create an instance of the user object and assign it to that variable.
-
Specify the particular Pipeline object you want to use.
To do this, code an Assignment statement in an appropriate script; assign a string containing the name of the desired Pipeline object to the DataObject property of your user-object instance.
For more information on coding the CREATE and Assignment statements, see the section called “CREATE” in PowerScript Reference and the section called “Assignment” in PowerScript Reference.
Example
The following sample code takes care of these pipeline setup chores in the order entry application.
Connecting to the source and destination database
In this case, the company's sales database (ABNCSALE.DB) is used as both the source and the destination database. To establish the necessary connections to the sales database, write code in a user event named uevent_pipe_setup (which is posted from the Open event of the w_sales_extract window).
The following code establishes the source database connection:
// Create a new instance of the Transaction object // and store it in itrans_source (a variable // declared earlier of type transaction). itrans_source = CREATE transaction // Next, assign values to the properties of the // itrans_source Transaction object. ... // Now connect to the source database. CONNECT USING itrans_source;
The following code establishes the destination database connection:
// Create a new instance of the Transaction object // and store it in itrans_destination (a variable // declared earlier of type transaction). itrans_destination = CREATE transaction // Next, assign values to the properties of the // itrans_destination Transaction object. ... // Now connect to the destination database. CONNECT USING itrans_destination;
Setting USERID for native drivers
When you execute a pipeline in the Pipeline painter, if you are using a native driver, PowerBuilder automatically qualifies table names with the owner of the table. When you execute a pipeline in an application, if you are using a native driver, you must set the USERID property in the Transaction object so that the table name is properly qualified.
Failing to set the USERID property in the Transaction object for the destination database causes pipeline execution errors. If the source database uses a native driver, extended attributes are not piped if USERID is not set.
Creating an instance of the user object
Earlier you learned how to develop a supporting user object named u_sales_pipe_logistics. To use u_sales_pipe_logistics in the application, first declare a variable of its type:
// This is an instance variable for the // w_sales_extract window. u_sales_pipe_logistics iuo_pipe_logistics
Then write code in the uevent_pipe_setup user event to create an instance of u_sales_pipe_logistics and store this instance in the variable iuo_pipe_logistics:
iuo_pipe_logistics = CREATE u_sales_pipe_logistics
Specifying the Pipeline object to use
The application uses one of two different Pipeline objects, depending on the kind of piping operation the user wants to perform:
-
pipe_sales_extract1 (which you saw in detail earlier) creates a new Quarterly_extract table (and assumes that this table does not currently exist)
-
pipe_sales_extract2 inserts rows into the Quarterly_extract table (and assumes that this table does currently exist)
To choose a Pipeline object and prepare to use it, write the following code in the Clicked event of the cb_write CommandButton (which users click when they want to start piping):
// Look at which radio button is checked in the // w_sales_extract window. Then assign the matching // Pipeline object to iuo_pipe_logistics. IF rb_create.checked = true THEN iuo_pipe_logistics.dataobject = "pipe_sales_extract1" ELSE iuo_pipe_logistics.dataobject = "pipe_sales_extract2" END IF
This code appears at the beginning of the script, before the code that starts the chosen pipeline.
Deploying Pipeline objects for an application
Because an application must always reference its Pipeline objects dynamically at runtime (through string variables), you must package these objects in one or more dynamic libraries when deploying the application. You cannot include Pipeline objects in an executable (EXE) file.
For more information on deployment, see Part 9, "Deployment Techniques".
With the setup chores taken care of, you can now start the execution of your pipeline.
To start pipeline execution:
-
Code the Start function in an appropriate script. In this function, you specify:
-
The Transaction object for the source database
-
The Transaction object for the destination database
-
The DataWindow control in which you want the Start function to display any error rows
The Start function automatically associates the PowerBuilder pipeline-error DataWindow object with your DataWindow control when needed.
-
Values for retrieval arguments you have defined in the Pipeline object
If you omit these values, the Start function prompts the user for them automatically at runtime.
-
-
Test the result of the Start function.
For more information on coding the Start function, see the section called “Start” in PowerScript Reference.
Example
The following sample code starts pipeline execution in the order entry application.
Calling the Start function
When users want to start their selected pipeline, they click the cb_write CommandButton in the w_sales_extract window:
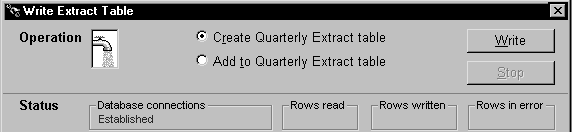
This executes the Clicked event of cb_write, which contains the Start function:
// Now start piping. integer li_start_result li_start_result = iuo_pipe_logistics.Start & (itrans_source,itrans_destination,dw_pipe_errors)
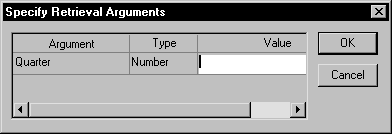
Notice that the user did not supply a value for the pipeline's retrieval argument (quarter). As a consequence, the Start function prompts the user for it:
Testing the result
The next few lines of code in the Clicked event of cb_write check the Start function's return value. This lets the application know whether it succeeded or not (and if not, what went wrong):
CHOOSE CASE li_start_result
CASE -3
Beep (1)
MessageBox("Piping Error", &
"Quarterly_Extract table already exists ...
RETURN
CASE -4
Beep (1)
MessageBox("Piping Error", &
"Quarterly_Extract table does not exist ...
RETURN
...
END CHOOSETesting the Start function's return value is not the only way to monitor the status of pipeline execution. Another technique you can use is to retrieve statistics that your supporting user object keeps concerning the number of rows processed. They provide a live count of:
-
The rows read by the pipeline from the source tables
-
The rows written by the pipeline to the destination table or to the error DataWindow control
-
The rows in error that the pipeline has written to the error DataWindow control (but not to the destination table)
By retrieving these statistics from the supporting user object, you can dynamically display them in the window and enable users to watch the pipeline's progress.
To display pipeline row statistics:
-
Open your supporting user object in the User Object painter.
The User Object painter workspace displays, enabling you to edit your user object.
-
Declare three instance variables of type StaticText:
statictext ist_status_read, ist_status_written, & ist_status_errorYou will use these instance variables later to hold three StaticText controls from your window. This will enable the user object to manipulate those controls directly and make them dynamically display the various pipeline row statistics.
-
In the user object's PipeMeter event script, code statements to assign the values of properties inherited from the pipeline system object to the Text property of your three StaticText instance variables.
ist_status_read.text = string(RowsRead) ist_status_written.text = string(RowsWritten) ist_status_error.text = string(RowsInError)
-
Save your changes to the user object, then close the User Object painter.
-
Open your window in the Window painter.
-
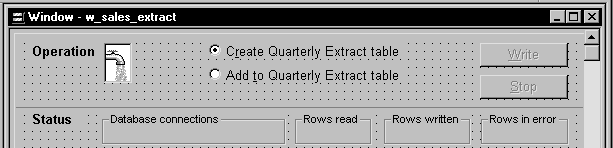
Insert three StaticText controls in the window:
One to display the RowsRead value
One to display the RowsWritten value
One to display the RowsInError value
-
Edit the window's Open event script (or some other script that executes right after the window opens).
In it, code statements to assign the three StaticText controls (which you just inserted in the window) to the three corresponding StaticText instance variables you declared earlier in the user object. This enables the user object to manipulate these controls directly.
In the sample order entry application, this logic is in a user event named uevent_pipe_setup (which is posted from the Open event of the w_sales_extract window):
iuo_pipe_logistics.ist_status_read = st_status_read iuo_pipe_logistics.ist_status_written = & st_status_written iuo_pipe_logistics.ist_status_error = & st_status_error -
Save your changes to the window. Then close the Window painter.
When you start a pipeline in the w_sales_extract window of the order entry application, the user object's PipeMeter event triggers and executes its code to display pipeline row statistics in the three StaticText controls:

In many cases you will want to provide users (or the application itself) with the ability to stop execution of a pipeline while it is in progress. For instance, you may want to give users a way out if they start the pipeline by mistake or if execution is taking longer than desired (maybe because many rows are involved).
To cancel pipeline execution:
-
Code the Cancel function in an appropriate script
Make sure that either the user or your application can execute this function (if appropriate) once the pipeline has started. When Cancel is executed, it stops the piping of any more rows after that moment.
Rows that have already been piped up to that moment may or may not be committed to the destination table, depending on the Commit property you specified when building your Pipeline object in the Data Pipeline painter. You will learn more about committing in the next section.
-
Test the result of the Cancel function
For more information on coding the Cancel function, see the section called “Cancel” in PowerScript Reference.
Example
The following example uses a command button to let users cancel pipeline execution in the order entry application.
Providing a CommandButton
When creating the w_sales_extract window, include a CommandButton control named cb_stop. Then write code in a few of the application's scripts to enable this CommandButton when pipeline execution starts and to disable it when the piping is done.
Calling the Cancel function
Next write a script for the Clicked event of cb_stop. This script calls the Cancel function and tests whether or not it worked properly:
IF iuo_pipe_logistics.Cancel() = 1 THEN
Beep (1)
MessageBox("Operation Status", &
"Piping stopped (by your request).")
ELSE
Beep (1)
MessageBox("Operation Status", &
"Error when trying to stop piping.", &
Exclamation!)
END IFTogether, these features let a user of the application click the cb_stop CommandButton to cancel a pipeline that is currently executing.
When a Pipeline object executes, it commits updates to the destination table according to your specifications in the Data Pipeline painter. You do not need to write any COMMIT statements in your application's scripts (unless you specified the value None for the Pipeline object's Commit property).
Example
For instance, both of the Pipeline objects in the order entry application (pipe_sales_extract1 and pipe_sales_extract2) are defined in the Data Pipeline painter to commit all rows. As a result, the Start function (or the Repair function) will pipe every appropriate row and then issue a commit.
You might want instead to define a Pipeline object that periodically issues commits as rows are being piped, such as after every 10 or 100 rows.
If the Cancel function is called
A related topic is what happens with committing if your application calls the Cancel function to stop a pipeline that is currently executing. In this case too, the Commit property in the Data Pipeline painter determines what to do, as shown in the following table.
|
If your Commit value is |
Then Cancel does this |
|---|---|
|
All |
Rolls back every row that was piped by the current Start function (or Repair function) |
|
A particular number of rows (such as 1, 10, or 100) |
Commits every row that was piped up to the moment of cancellation |
This is the same commit/rollback behavior that occurs when a pipeline reaches its Max Errors limit (which is also specified in the Data Pipeline painter).
For more information on controlling commits and rollbacks for a Pipeline object, see the section called “Whether rows are committed” in Users Guide.
When a pipeline executes, it may be unable to write particular rows to the destination table. For instance, this could happen with a row that has the same primary key as a row already in the destination table.
Using the pipeline-error DataWindow
To help you handle such error rows, the pipeline places them in the DataWindow control you painted in your window and specified in the Start function. It does this by automatically associating its own special DataWindow object (the PowerBuilder pipeline-error DataWindow) with your DataWindow control.
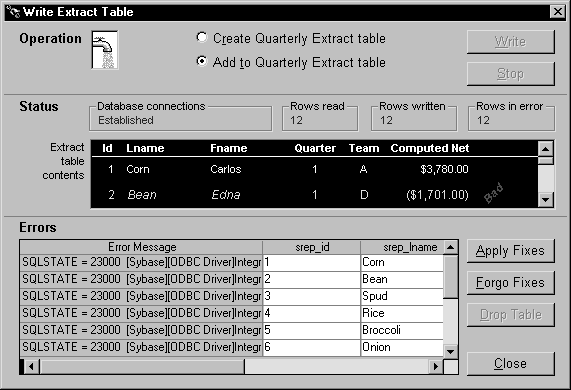
Consider what happens in the order entry application. When a pipeline executes in the w_sales_extract window, the Start function places all error rows in the dw_pipe_errors DataWindow control. It includes an error message column to identify the problem with each row:
Making the error messages shorter
If the pipeline's destination Transaction object points to an ODBC data source, you can set its DBParm MsgTerse parameter to make the error messages in the DataWindow shorter. Specifically, if you type:
MsgTerse = 'Yes'
then the SQLSTATE error number does not display.
For more information on the MsgTerse DBParm, see the section called “MsgTerse” in Connection Reference.
Deciding what to do with error rows
Once there are error rows in your DataWindow control, you need to decide what to do with them. Your alternatives include:
-
Repairing some or all of those rows
-
Abandoning some or all of those rows
In many situations it is appropriate to try fixing error rows so that they can be applied to the destination table. Making these fixes typically involves modifying one or more of their column values so that the destination table will accept them. You can do this in a couple of different ways:
-
By letting the user edit one or more of the rows in the error DataWindow control (the easy way for you, because it does not require any coding work)
-
By executing script code in your application that edits one or more of the rows in the error DataWindow control for the user
In either case, the next step is to apply the modified rows from this DataWindow control to the destination table.
To apply row repairs to the destination table:
-
Code the Repair function in an appropriate script. In this function, specify the Transaction object for the destination database.
-
Test the result of the Repair function.
For more information on coding the Repair function, see the section called “Repair” in PowerScript Reference.
Example
In the following example, users can edit the contents of the dw_pipe_errors DataWindow control to fix error rows that appear. They can then apply those modified rows to the destination table.
Providing a CommandButton
When painting the w_sales_extract window, include a CommandButton control named cb_applyfixes. Then write code in a few of the application's scripts to enable this CommandButton when dw_pipe_errors contains error rows and to disable it when no error rows appear.
Calling the Repair function
Next write a script for the Clicked event of cb_applyfixes. This script calls the Repair function and tests whether or not it worked properly:
IF iuo_pipe_logistics.Repair(itrans_destination) &
<> 1 THEN
Beep (1)
MessageBox("Operation Status", "Error when &
trying to apply fixes.", Exclamation!)
END IFTogether, these features let a user of the application click the cb_applyfixes CommandButton to try updating the destination table with one or more corrected rows from dw_pipe_errors.
Canceling row repairs
Earlier in this chapter you learned how to let users (or the application itself) stop writing rows to the destination table during the initial execution of a pipeline. If appropriate, you can use the same technique while row repairs are being applied.
For details, see Canceling pipeline execution.
Committing row repairs
The Repair function commits (or rolls back) database updates in the same way the Start function does.
For details, see Committing updates to the database.
Handling rows that still are not repaired
Sometimes after the Repair function has executed, there may still be error rows left in the error DataWindow control. This may be because these rows:
-
Were modified by the user or application but still have errors
-
Were not modified by the user or application
-
Were never written to the destination table because the Cancel function was called (or were rolled back from the destination table following the cancellation)
At this point, the user or application can try again to modify these rows and then apply them to the destination table with the Repair function. There is also the alternative of abandoning one or more of these rows. You will learn about that technique next.
In some cases, you may want to enable users or your application to completely discard one or more error rows from the error DataWindow control. This can be useful for dealing with error rows that it is not desirable to repair.
The following table shows some techniques you can use for abandoning such error rows.
|
If you want to abandon |
Use |
|---|---|
|
All error rows in the error DataWindow control |
The Reset function |
|
One or more particular error rows in the error DataWindow control |
The RowsDiscard function |
For more information on coding these functions, see the section called “Reset” in DataWindow Reference and the section called “RowsDiscard” in DataWindow Reference.
Example
In the following example, users can choose to abandon all error rows in the dw_pipe_errors DataWindow control.
Providing a CommandButton
When painting the w_sales_extract window, include a CommandButton control named cb_forgofixes. Write code in a few of the application's scripts to enable this CommandButton when dw_pipe_errors contains error rows and to disable it when no error rows appear.
Calling the Reset function
Next write a script for the Clicked event of cb_forgofixes. This script calls the Reset function:
dw_pipe_errors.Reset()
Together, these features let a user of the application click the cb_forgofixes CommandButton to discard all error rows from dw_pipe_errors.
When your application has finished processing pipelines, you need to make sure it takes care of a few cleanup chores. These chores basically involve releasing the resources you obtained at the beginning to support pipeline execution.
Garbage collection
You should avoid using the DESTROY statement to clean up resources unless you are sure that the objects you are destroying are not used elsewhere. PowerBuilder's garbage collection mechanism automatically removes unreferenced objects. For more information, see Garbage collection and memory management.
To clean up when you have finished using pipelines:
-
Destroy the instance that you created of your supporting user object.
To do this, code the DESTROY statement in an appropriate script and specify the name of the variable that contains that user-object instance.
-
Disconnect from the pipeline's source and destination databases.
To do this, code two DISCONNECT statements in an appropriate script. In one, specify the name of the variable that contains your source transaction-object instance. In the other, specify the name of the variable that contains your destination transaction-object instance.
Then test the result of each DISCONNECT statement.
-
Destroy your source transaction-object instance and your destination transaction-object instance.
To do this, code two DESTROY statements in an appropriate script. In one, specify the name of the variable that contains your source transaction-object instance. In the other, specify the name of the variable that contains your destination transaction-object instance.
For more information on coding the DESTROY and DISCONNECT statements, see the section called “DESTROY” in PowerScript Reference and the section called “DISCONNECT” in PowerScript Reference.
Example
The following code in the Close event of the w_sales_extract window takes care of these cleanup chores.
Destroying the user-object instance
At the beginning of the Close event script, code the following statement to destroy the instance of the user object u_sales_pipe_logistics (which is stored in the iuo_pipe_logistics variable):
DESTROY iuo_pipe_logistics
Disconnecting from the source database
Next, code these statements to disconnect from the source database, test the result of the disconnection, and destroy the source transaction-object instance (which is stored in the itrans_source variable):
DISCONNECT USING itrans_source;
// Check result of DISCONNECT statement.
IF itrans_source.SQLCode = -1 THEN
Beep (1)
MessageBox("Database Connection Error", &
"Problem when disconnecting from the source " &
+ "database. Please call technical support. " &
+ "~n~r~n~rDetails follow: " + &
String(itrans_source.SQLDBCode) + " " + &
itrans_source.SQLErrText, Exclamation!)
END IF
DESTROY itrans_sourceDisconnecting from the destination database
Finally, code these statements to disconnect from the destination database, test the result of the disconnection, and destroy their destination transaction-object instance (which is stored in the itrans_destination variable):
DISCONNECT USING itrans_destination;
// Check result of DISCONNECT statement.
IF itrans_destination.SQLCode = -1 THEN
Beep (1)
MessageBox("Database Connection Error", &
"Problem when disconnecting from " + &
"the destination (Sales) database. " + &
"Please call technical support." + &
"~n~r~n~rDetails follow: " + &
String(itrans_destination.SQLDBCode) + " " + &
itrans_destination.SQLErrText, Exclamation!)
END IF
DESTROY itrans_destination